While re-going though some Incident response topics with Security Blue Team, Cybary and LinkedIn Learning there was a common thread that they all had if they were going though NIST 800-61 (or even SANS standards) was NOT to skip the post incident activities. business is back up right? who cares? we got it all solved so post incident activities means going out to the local watering hole and having an adult beverage or six. That is what you mean right? No. not at all (although if you wanted to post post incident activities I guess this could work)
Now your might be thinking why well if your are a fan of standards/frameworks (If you are in Cyber you probably are since you do have compliance you need to meet among other things) there is this hole step that can also improve the process for next time, as it is going to happen as someone is going to have an off day and click yet another link to make your life full of fun. Also you wouldn’t hire a Pen-testing firm to come in and not review the findings and look for ways to improve the organizations security posture? You wouldn’t do Red team/purple team engagement with tools like Red Canary’s “Atomic Red Team” or MITRE Caldera would you? If not what are you really getting out of it other than doing a task to check the box for something which is not going to do anything to help you or the org (except maybe if you want to give yourself a gold star). You use these tools and skills to look at oversights, detection/alerts that are missing or not as clear. Which you would work to fix and to help your cause you could map this to ATT&CK/Shield (as we all know leaderships likes charts and frameworks are super helpful for some).
So the question is, we make time for that? why are we not making time for the post incident review? I get it. its another round table, another day potently spent going over process/procedures but if it makes your security posture better by looking at the things you would with a Pen-Test or purple teaming, why skip out on it. It’s like stomping out a fire without making sure it’s embers are fully out. In this case you don’t improve the response to a particular incident guess what happens? those embers (incident) rises into a flame and next thing you know you are dealing with a similar incident responding in the same way. Did that really work? sure you put out the big fire, but you did not ensure it was fully out because you are still getting hit in the same way you did before. now if your org is not giving you the time or capabilities to fully put out the fire, you probably do not have full management buy in into your incident response program as that should be the priority for those on the Computer Emergency Repose Team (CERT/Cyber Security Incident Response Team (CSIRT) when facing an incident.
I do understand that most are working with limited business and that security is just a coast center (unless you are an MSSP or something among those lines). but how can the business really function under normal operations if you still have kindling flames of incidents (attack vectors that your IR plan/policy lacks coverage for) if you are constantly wasting time going back to “remediating” and leaving it at that. Maybe its the military and having to instruct a few classes that thought me the importance of After Action Reviews (AAR) but not doing that security incidents and then wondering why you are dealing with the same attacks over and over again fits the definition of insanity (doing the same thing over again and expecting a different result). Doubly so if the business gets effected by this time after time, you would think they would want it to be prevented to prevent any bad publicity and having to issues statements over and over again.
Taking the time to try and close the gap with post incident activities ensure senior leadership understand that this is apart of the process and ensure that it is the plan/policy. if they do not want to listen and want you to move on to other things remind them of their buy in/enforcement. If not, use ethics committees and other tools to ensure policies/plans/procedures are being enforced and allowed to be followed though to the end, the very end. At the end of the day this is to better the security posture to allow an org to keep operations up by having plans in place to avoid shutting down production due to a cyber incident that effects the CIA triad.
I know not every org is like this, but when going though videos and other training the theme that always seems to be around is “DO NOT SKIP THE POST INCIDENT ACTIVITIES” there is defiantly something up with the industry and something we need ensure we are doing. Along with doing IR exercises (if you want some gamification of IR tabletops look at Black Hills Information Security Backdoors and Breaches card game) But I’ll save that for another time.
A few days later as been pretty busy with some house work, and forgot I was on call this week and had a fun situation to deal with on Friday. Day 4 was better sweet as it was the last day of training and this really started to get a community vibe to it. To be honest it feels a little odd not interacting with everyone. We started today off with some fun! Nmap and using responded to get LLMNR passwords and John the Ripper before moving on to allow list (versus Deny list, which I have been living on and make me sad). Malware and allow list, open DNS and domain name (which I had to re-watch as I missed out on this as I had an appointment for an hour…part of the reason for the delay), Vulnerability management, threat emulation (again) before some DevSecOps/SDLC/Webapps and automated testing with ZAP! There was some breif talk about AD hardening, Plumhound (Blood hound for purple/blue teams). Breif talk on Mimikatz/Ping Castle, Cyber deception and some last little bit of off roading with Active Defense Harbinger Distribution).
Deny list do not work well, is A) you generally going to be behind trying to add “new” IP’s/Domains is that the internet is HUGE, and generally once those “new IP’s/Domains get added, they are already old and attackers might of found a new site to take over/hijack. Not to mention even with ALL the great user awareness training someone is going to have a bad day and click the link. Going back to the other point it is super easier for attackers to get domains by buying existing or expired domains. Instead Allow list categories (as adding ALL the sites by themselves is a bad idea). You can be compromised with a legit/”good” site with drive by downloads (malvertisement for example were the dropper or a bad link could be place in an ad on the legit site and next think you know, you are talking to a C2 Site/Server). There was a good conversation about using OpenDNS for home use to help allow list to protect yourself at home, Which I have been playing around with that and tinkering with a PiHole (but I still need to talk to my wife about getting our own cable modem/router as PiHole and ISP all in ones do not mix..). There was a pretty good discussion on DNS over HTTPS while its good that it is now encrypted and protected, but the issue is that defenders in the enterprise is you lose visibility
John had some really good tips with vulnerability management and still running same program as they were 10+years ago. Vendors have not changed and test/scans for internal/external vulnerabilities. Seems simple right? who needs to think about it and no real new innovation at all. But John also noted to use authenticated scans (which is a risk, as that account can have read only into the servers and other assets that it scans and uses that account for, and if it gets owned, you can be up a creak without a paddle.) Do it, having done some stuff with Tenable/Nessus un-authenticated scans look like a glorified NMAP scan and really do not give you much. You are better off authenticated OR if you can support it using agents. John went on what we called a STRANT or a STRAND RANT, Which can be summarized with the snap from the slides
AKA Garbage copy write Black Hills Information Security/John Strand.
You need to see the context of vulnerabilities even with Low/informational issues as attackers might start with those low/information issue and use them as the straw to break the camels back, and gain access via the medium/low/informational. You need to look are more than an IP list to freak out, a good slide again (not going to share this one) but you want to break it up by IP address to help make it easier to look at and go by patch and fix that computer with that IP…and is stupid and don’t do it. the magic?
GROUP BY VULNERABILITY-NOT IP ADDRESS (AKA the crap the report spits out). instead of worrying about the total vulnerabilities you have to deal with a few that repeat on certain systems and use the tools to focus on that group of issues. IANS faculty have used this (versus the listing by IP) and addressed over 1 million IP address, all vulnerabilities in less than 3 weeks. To help think of this vulnerabilities as more than missed patches or bad configs, think about what could happen with post exploitation, what happens after an attacker gains access? this is were threat emulation can help direct with the low hanging fruit and get those vulnerabilities address. I did miss a chunk of this discussion and it was brought up that vulnerability scanners are getting hardening tools/tips and can also implement CIS benchmarks in the case of Tenable for example, but they still have a long way to go and do not work as well as one would hope.
When talking about Software Development Lifecycle (SDLC) it was talked about how security is just bolted on at the end, which frankly does not work at all and just leaves issues. One of the problems is people want to do it quick, cheeply and because it takes time (because security is hard) versus having it be done along with the software development. Fun fact is that most security testers know less about development as it is a different skill set, and it is easier to teach a web developer some basic security practice using free tools that can be used. Using tools to test should be done by a different team member (it helps to have a different set of eyes than the one doing the development). The tools are easy to use and should be done weekly as a best practice (even better if done nightly) and it will make you a better developer because you will start having code/applications that are less vulnerability and you will become more effective.
Don’t worry about testing for the crazy new hotness 0 day vulnerability get the low hanging fruit like:
Cross Site Scripting
SQL Injection
Command Injection
Misconfigurations
This takes away a large suface area and gets rid of the easy attacks. Most attackers are going to look for the easy way in, and not try complex attacks unless your dealing with an ATP (nation state group) or someone who is targeting the company, which if you have proper NSM,application/server logs, logs from perimeter network defense (like Firewalls, NIDS/NIPS, Web Application Firewall (WAF)) you might notice someone knocking on your door. While these tools do help test a lot of things, they do not get logic errors, permission errors, stored cross site scripting, cross site request forgery as they need manual testing. John also brought up a good point, self test and fix the easy vulnerabilities before you get an external test. Do you really want an external test done were you get handed a bunch of XSS (Cross site scripting) attacks or rather make the testers look for the logic errors or harder issues at hand and allow you to get more value for test. Really though these self test should happen on the regular. what are those tools? Burp Pro is awesome (and pretty cheep) and of course everyone’s favorite OWASP Zed Attack Proxy (ZAP) and went over laps on how they are used and set up (which since there are free version of burp and ZAP is open source, there are plenty of resources out there for getting started with these tools.
We then started to wrap up to the focus we need to stop focusing on “can we be hacked?” to “what can we detect?” start with finding gaps, trying to fill them and move on. John noted to “steal this idea/framework” and use these tools to at lest get started and to show worth if you want to spend the $$$, but lets be real, how much budgets to must Cyber Security/Information Security teams have? (news flash not a lot, unless you have an organization that has A)either gotten breached, or B) has a good security culture). Before warping up we talked about AD hardening and using a tool like plumb hound to look for ways to harden AD, and talked about Honey accounts (spoofed domain admins for example) which lead into the pivot point of using Honeybadger which is apart of ADHD. John had one last slide about Threat intel and how it should be your AV/Firewall/EDR vendors doing that work and to make actual threat Intel with things you are noticing on your decoys and were threat emulation found weak spots use that information to start hunting in the environment for possible attackers.
I’m slowly plucking away at getting my lab set up were I will hopefully have ADHD set up so I can write about that..uh..fun adventure. As I already put the firewall I set in transparent operation mode and pretty much killed the internet in my home, which lead to an annoyed wife :P. Still made add some things to this Lab that John gave us (like wirehsark to look at the actual traffic going on and get better with wireshark..I’d say TCP Dump but Linux subsystems…)
Today we shifted from logs and NSM and pivoted over to the endpoint with Advance Endpoint defection (Think Endpoint Detection and Responses…aka EDR). Or for you new TLA XDR or Extended Detection Response…but that covers more than just endpoint..and is above the scope of this blog. Gee I just got started with this and I’m already going off course…ANYWHO. We also looked at how to test what your end points are able to detect with tools like atomic red team, bloodhound the labs focused on today on using blue spawn (open source EDR) with atomic red team and even our little “exploit” we created back when we tested in app locker. There was also a touch on using host based firewalls and segmented networks (even by endpoint!) and a touch about architecture and needing not just defense in depth/layer security but overlapping segments. So you know your weak points and know what coverage you have is something fails.
Like mentioned before EDR is better than your traditional normal run of the mil AV and standard endpoint defense , which isn’t super helpful (though I guess EDR is going to be coming more of a standard). EDR products look at asset holistically and looks at processes and connections, which in DFIR world, is a huge advantage because you have a the chain of events that happened on the end point which in turn can help with the whole cyber kill chain. EDR can need some tuning work depending on certain processes that are being ran by system admins. Now you have an EDR solution and want to make sure it is detecting/alerting/monitoring things. This is were threat emulation can come into play, even if you are not full on red teaming but this can be useful to see how your EDR solution is working, or even other products within your environment as well. Instead of just the normal pop a vulnerability or missing patches or everyone’s favorite miss configured services, it goes into what happens after an attacker gets access (if you think your not going to get breached, hate to share bad news, but its going to happen). This help with lateral movement, different processes that could be used to try and escalate privilege, or infect system. I was really excited to do these labs with Blue Spawn (free open source “EDR”…not useful for full prod but for testing out the tools coming up, super useful).
We discussed Caldera which is created by the folks at MITRE (aka the people who created ATT&CK), Atomic Red Team, and Blood Hound. Caldaera and Atomic Red team can on assets and if you have your EDR/End point protection services in monitoring/alerting, While Bloodhound can map how an attacker could get admin/full domain admin permissions in your network. It was great to play with Atomic Red Team (I say that as I am currently wearing one of their swag shirts) and see how it works. The one point John made is not to be afraid of running these tools, even if it borks/breaks things. It just means you are doing your job even in an IT role of you don’t have a “whoops” moment (I myself have taken down our SIEM at work…was a good time). The other point is if you were worried about back doors in these open source tools, how many back doors have been found in other products? firewalls, endpoints, networking equipment all have been found with Backdoors on them. John also mentioned that while these tools are great. Don’t focus on the ATT&CK Bingo and blocking all the ATT&CK. Attacks change and with a few changes your not detecting it and bypass. This is were the commercial offerings can come into play (like Scythe, Attack IQ) to go around the basic ATT&CK building blocks and can use customer attack methods to check what you detect.
The last section was host based Firewalls, if your not segmenting your networks, plz start. All the way down to your desktop and between subnets as pass the hash/ticket and SAT impersonations have worked. You need to assuming you are going to get compromised/pwned (for real). What is really bad, attacker persisting and being able to move laterally/ and pivoting systems. John had some good images showing different things that might not show alerts (not going to copy as an encouragement to take the course in November). You can even just use the default windows firewall, but news flash: most of your endpoint protection vendors have built in firewalls as well and can be centrally managed and are far easier to be used than the netsh advfirewall.
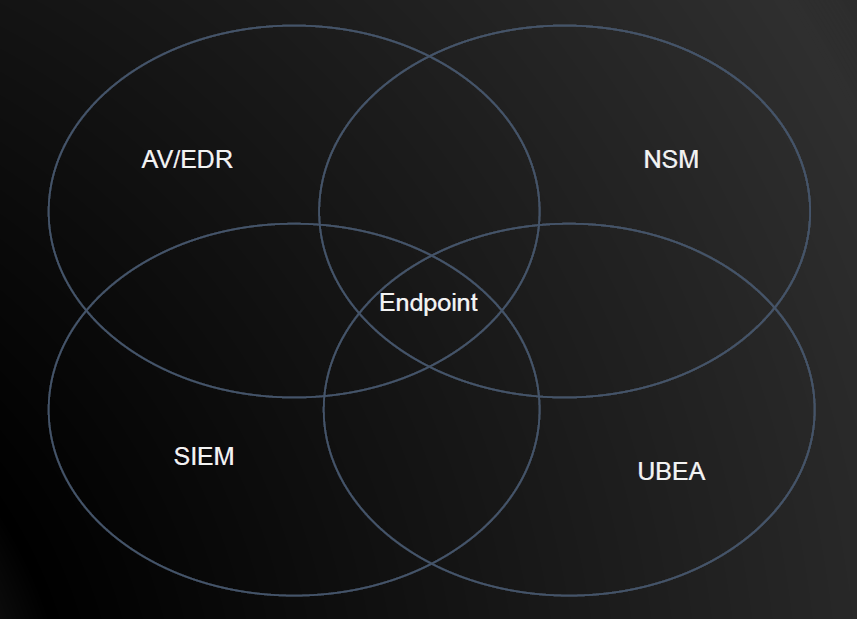
Remember with all of these, think about how they overlap and look for potential weak spots and look at how they can mitigated and ensure you have overlap going over the endpoint/assets to help have a good basic security architecture. I do like how John did break it down into overlaps versus the defense in depth. As normally people think firewall, IDS/NIPS, Endpoint protection but think of it like this:
Chart that John Stand had to show overlap between Network Security Monitoring (NSM-Sec Onion/Rita, Firewall alerts/signatures/traffic), netflows) Securtiy Incident Event Manager (SIEM), the Combo Plater of AV/Endpoint Detection Reponse (EDR) and UBEA (See Blog post from yesterday…User and Entirety Behavioral Analytics (UEBA, or noted as UBEA here)
I think this is super useful to think about versus the castle or other methods. We also did a quick talk on PVLAN’s were the firewall helps control access to the vlans (I need to look at this more).
Since the Nmap lab and Shodan off roading adventure is almost over, Time to get back to paying attention today to the last day. Doubly so since I am going miss an hour or so due to doctors. Thankfully some of these last topics are stuff I do with my day to day so it wont be to bad 🙂 with a hopeful bonus section on using ADHD 🙂
Was hoping to get this up after the course in the evening after some time to reflect, but I had to do battle with a lawn mower XD. Today there was a 20 minute pre show banter going over Metasploit/Meterpreter as it was used the other day and some information with lanman and NTLM password hashes before moving on into all the fun with LOGS (Do you have the log theme from Ren and Stimpy stuck in your head? I hope so)
This is sure to help!
While that was only a part of the topics we covered they were egress traffic monitoring/visibility before moving into user entity behavior analytics (Or for you acronym types UEBA…and for you QRadar types, the UBA). Lots of stuff was covered, the thing that made me happy was no “YOU NEED FIREWALL LOGS!!!!!” (Sure maybe in a log aggregator with more critical events going to the SIEM, but to flood it with single SSH connections….talk about a log toilet for your SIEM). The egress traffic mostly dealt with flows and PCAPS to look for long connections/beconing (or heart beats/jitter to C2/C&C servers) and looking at how big of a pain it is to set up proper logging with Windows, or you know…use sysmon and save yourself. There was also a breif talk about Sigma rules (which I also found uncoder.io to help translate sigma rules or other SIEM Rules (for the quick TL;DR)
The first key point we talked again was the egress traffic monitoring, which helps fit the bill if you are using the c2/C&C (Command and control) and exfiltration on MITRE ATT&CK. We need more than alerts (it really isn’t enough without the proper context, As someone that works in a SIEM a lot…can I get an amen?). by properly monitoring/logging of the egress traffic you can help see other OT/IoT/Shadow IT devices that is egressing so you can see what you mgiht be missing with an asset inventory or to spot check where NAC (network access controls) Might be failing. When you think Egress traffic a lot of people think “The firewalls” which is nice to see that traffic, however do you really want to fill your SIEM with just Firewall logs? Because it’s what you are likely going to do. That being said you need a balanced mix of network and host based data. A good example of this would be having your IDS alerts, any threat logs from Firewalls, a network flow (like Cisco’s netflow) to see the simple traffic (Ip/mac/port/basic packet info), and logs from the end point or server. Another helpful tool we talked about it Zeek (formally Bro) which is an open source network analysis frame work. Helps with constancy, and because open source has a lot of support. It also Helps with timestamps, which are key when doing analysis/network forensics and helps get proper log files and to see what is really going on versus waiting for the typical signatures (aka last weeks attack). Zeek can also takes full PCAPS for analysis (which you can look at if you want to use other tools which we covered later).
There was a brief on Hunt teaming (red team) with actively looking for threats and the joys of going though Logs (see above image) and using Active Countermeasures free tool RITA (Real Intelligence Threat Analytics) to look for long connections/beacons and can even check for Blacklist DNS as well. We than talked about Full PCAPS (which can put a lot of strain on network traffic if not being done carefully with the right tools). Everything supports PCAPS, there is a learning curve (a good course is the Security Blue Team intro to network analysis course which covers both Wireshark and TCP Dump and gives you PCAP’s to play with LINK I am sure there are others as well). It was nice that they showed an example of how to set up RITA to capture the traffic.
From this we pivoted into User agent string examples that you might see with some of the traffic captures that might be long/repetitive connections to Microsoft services for example or web browser and JA3 for profiling SSL/TLS clients. Because security does involve math (yay…)Long Tail analysis was brought up to look for anomalies and outliers (If you went to school for Cyber/Information security and thought taking a statistics class, I got news for you, you use it a lot). never try and find the “needle in the haystack” but look for the odd traffic and possible anomalies. John than gave a shot out to Security Onion, which is the next thing I plan on setting up for a lab to help monitor what will be going on with my purple team lab and my normal home network). Comes with Zeek, Suricata, ELK and other useful features.
UEBA, Hurray! (which means if you were in the course, this blog is almost done XD). Just a reminder. There is no “YOU GOT PWNED” Log and only 5% of detects come from logs and traditional windows logs are not super useful for security. You can use tools from JPCert Tools to try and help, but that can be a lot of extra overhead and different tool usage. Why do this? These logs can help tell the story with AD, Exchange, OWA and other system/system access. News flash: This requires Tuning, as security professionals not red teaming this is our job. If you just set up a blinky box and expect it to do all your work its not. things are going to get missed (because blinky boxes like signatures or certain events). A good example is internal password spray. One ID, accessing multiple systems However this brings into view the “False Positives” (which is a rant I have with Qradar with the tuning calling things False Positives” its not really a thing, it’s not normal traffic and not tuned properly, think system/service accounts trying to log into multiple services (think that internal password spray example). System admins, scripts *Groan* and back ups. It is why tuning is so critical, if your managers, CISCO/CIO don’t think it is important, there are tons of resources that point to the need of this, and is what a security team should be doing, and with that I’ll get off my soap box.
UEBA can works by stacking, like cards. a user log on +1, log off -1. Set a threshold (6) so if the user tries to log in 7 times or uses bloodhound they get A lot of log on attempts and should be some sort of alert generated. As much as I have a dislike with AI, UEBA can use AI to help learn what is normal and help with baselines, so it can have the basic logs of account log ins or data transfers and when user pulls a gig of files and is now pulling 5…you might got a problem (and can help with USB connections and other things). Now that we have logs, how do we get them. All of them, systems, servers, services, network *insert log theme here*. Getting the right logs takes time and is a pain and there are many factors that need to be taking in that can align with risk (data classification of data on asset, critical business assets among other factors). John brought up a good point with getting AD/Powershell/Command line logs. Its hard and its noisy, but what’s even harder? Not having UEBA or not having it at all. The logs can be used with tools like Logon Tracer to help see the movement across the network. Other helpful tools are DeepBlueCLI to help with a portable UEBA logs, while sucks for a full enterprise deployment, it can be useful in a lab setting to see what logs you need, or a nice tool for your DFIR toolkit. Same with DeepWhiteCLI, which works with parsing Sysmon event logs and grabbing the SHA256 hases to get process creation, driver load, and image load events. There was discussion with enabling windows event logging with important event ID’s but discussed setting up Command Line Logs/Powershell logs….a long procces, which to TL;DR is a long process. OR you can make your life easy with installing sysmon. You can install it locally (and SwiftOnSecurtiy default config install is a prime example). There is a great article from syspanda (https://www.syspanda.com/index.php/2017/02/28/deploying-sysmon-through-gpo/). To help deploy it enterprise wide via GPO. Another helpful service if your using ELK/Elastic is winlogbeat which does a nice and useful thing and sends all this info over to elk! And it can be messy going between different SIEM rules which is why Sigma is brought up briefly for sigma rules (which you can convert to the SIEM flavor of your choice, though Sigma is meant to be a non-vendor specific SIEM Rule). There was also a slide on exchange loging (and a best practice to enable log file and ETW event and the max size). We than did the Deep Blue CLI lab. I cannot remember if we talked about it but there was a slide from logon Tracer that focuses around 6 even ID’s
4624-Loggin Success
4625-Logon Failure
4768-Kerberos Authentication (TGT Request)
4769-Kerberos Service Ticket (ST Request)
4776-NTLM Authentication
4672-Assing special privileges
While I started zoning out as my system admin experience is limited but with the in detail how to log AD, Command Line (as a lot of malware/bad things run ping, tracert, and netstat), and powershell I was in the firehose effect and there was some about about Kerberorusting and other attacks as we started with Password Spraying.
I got a little lost at the end as I was trying to help out and there were SIEM questions and I’ll admit I was over logging at this point and agreeing with John’s point of view of SIEM and not fully knowing how much you log, and where you log from, who tells you what to log and finally what percent of those logs have an alert/signature for them. As someone who knew the SIEM at $employeer was a dumpster fire, I jumped in and got my hands dirty trying my best to fix the charlie foxtrot and learning a lot along the way as there are a lot of questions like this and I am trying to be more active with giving back and really seeing how much I know (and help my learn it better by trying to teach it)
Time to get get a little pump of coffee to get ready for today’s pre-show backdoor and breaches demo!
I was debating on doing this as a end of the week post with going over things that were discussed and things that I learned, but the shear amount of stuff getting covered i feel that’d just be a huge wall-o-text and need a TL;DR. While this is staying pretty wide over 11 topics that if you are doing, and doing well are a great starting point you can tell the team at Black Hills Information Security (BHIS) lead by John Strand there is still a lot…just not the firehouse SANS type or other “boot camp” styled courses.
Today the first day of the course which of course started with John going on some of his uhh…rants about treating your internal network as hostel (ie treat it like your local coffee shops network), don’t just use one security vendor/product, and compliance, which are ones I agree with in terms of compliance and just checking the box when really you should use compliance/audits to help push the org security posture. I know its easier said than done though as Security is a cost center so you need to apply proper risk to sell the point of doing more than just 7 character passwords for PCI-DSS as an example (even though its less of a requirement than the NIST green book from the 80’s…I Digress). We talked about the 11 controls/Key Tracking Indicators which they call the atomic controls they are:
Application Allow List
Password Controls (Good ole IAM)
Egreess Traffic Analysis
UEBA
Advance Endpoint Protection
Logging (which I noted properly, not just a log toilet for a SIEM)
Host (endpoint) Firewalls
Internet Allow List
Vulnerability Management (done properly based on Biz/org risk and actual asset inventory)
AD Hardening
Back up/recovery
I’m sure to anyone who has been in the security business will know some of these and also tieing some of these things into the MITRE ATT&CK Framework (which was a good point to not play ATT&CK Bingo/Jinga)
What was super ironic is right after this we pivoted to compliance. Learned about the useful tool of audit scripts to help with auditing with various compliance standards and see where you stand. Fun fact, everyone in the course went to the site and we may or may not of DDoS the site with a hug of death. This can help break things into smaller frameworks and can cross reference into your other core frameworks
For me the next part with the Application Allow list hit home, as dealing with doing Deny list on Proxy is a pain in the butt, I didn’t even think about it from an endpoint prospective. I watched this Live at a GrrCon talk were Dave Kenedy just updated Magic Unicorn and just change a character of text and he was owning his test windows box as windows defender and other products didn’t have that signature for the deny list. it was brought up in the course that attackers are breaking up power shell into different parts of scripts now. It was cool to look at Ghost writing aka making a ruby executable with meterpreter, make it a .asm file, edit the asm file, convert back to .exe and you are an infosec wizzard because you edited something in assembly (john’s joke). We also talked about encoding and AV bypass with encoding and obfuscation (see above with GrrCon example). We then went on Application whitelisting using Whitelisting Directories (simply only allowing applications to run in certain directories). While can be bypassed many initial access attacks (drive by downloads) are executed from the downloads, desktop, or temporary directories. Hash whitelisting was also discuses, but the ease of implementing and keeping up to date is a pain, just like Digital certs as not all vendors sign all their .exe or .dlls. For this course we used AppLocker (which I’ll admit it has been a minute since I heard anyone mention this). Native to Windows can whitelist and/or deny based on Path, Ash, Cert, vendor. We created a simple policy just with the defaults of allowing the program files, and windows directories. The on thing that could catch admins off guard is needing to turn on the windows service “Application identity” on the local systems (I’m assuming you could push this out from your AD network if needed) to be enabled. You also need to push the GPO out, as was a issue the demo gods did not like as you need to wait for replication between user accounts in our case.
The next fun was everyone’s favorite Password Controls (I can hear your groan from here). There was a good discussion on password spraying with everyone favorite <sesson><year> (I’m sure password or other default creds can be used if you know any of the devices from any recon you have done as people are smart and forget to tweek those or system accounts). Of course this requires a harvesting attack before the attacker will plug the ID’s into burp and try their best. Once that account is pwned without proper monitoring or UBA it can be hard to detect. We talked about two tools (credking and FireProx).
The big issue that was discussed is that just because you have 2FA/MFA org’s still have password policies between 8 and 10 characters. This only can be somewhat good if it is 2FA/MFA across the entire board, if not bad things are going to happen as you have a 8-10 charter passwords that can get pwned in as little as an hour or so (or even faster if the attacker has a password cracking rig). A good idea for compliance and auditing is having regular scanning of authentication points (with regular penitent-John). Regardless of 2FA/MFA encourage the use of passphrases, Just a few random words that make a phrase. still for complexity and to throw off password crackers add that might be using dictionary attacks (using common dictionary words to brute force passwords) ensure there are numbers and special characters. These can be easier for users to remember as they can use dictionary words to make a random phrase they can remember. You can also use a password manager with a good passphrase and 2FA to help you or your users with passwords (it can help avoid the password reuse or just changing 1 character). But with a password manager if it gets breached, all your accounts could be compromised (again no worse if you use the same password for everything so a good first step is to stop that).
There was some basic 2FA (as mentioned above) aka something you know and have. can be tokens, SMS, or app based (all are better than no 2FA). It was pointed out how to attack SMS 2FA with SIM cloning. After this brief talk on 2FA (as you can talk vendors and different ways to set up 2FA and this is just an intro course after all) We talked about the bane of just about any IT professionals work life, Service accounts. AKA accounts that are used by products to do things, or in scripts were when you change a password you could borked production on a Friday and be the on call guy and get to have an adventure. These need to have passwords that expire and have lockouts. Even if it causes an internal outage, they are used by attackers as they can be overlooked. We then applied what we learned about passwords and how fast they can be cracked with Hashcat. I was so used to John the Ripper from School (almost 3+ years now…crazy) and doing Rainbow tables (which was discussed how now effective they are compared to lets say Hashcat). I’ll admit I will probably have a blog post shortly with some Hashcat adventures once I get my home Lab fully set up, and when its not muggy/hot in my study (its upstairs and its currently in the mid 90’s and muggy, I don’t need a 1RU server making it even more toasty up here) and get some time with that to get more experience with it. Even as someone who is more on the Blue team/DFIR side of the house, understanding how this tools work allows you to better understand the risk they pose and possible attack vectors attackers might use when trying to get password hashes.
We didn’t get to password spraying today so that will be done tomorrow. Hopefully I remember to pop in the 1/2 hour early to get the quick refresher, might be useful for poking my deception systems at work when I am back to work to see how they are alerting XD
Looking foreword to tomorrow though with egress traffic analysis, as someone that is more analytical I love looking at logs and trying to make sense of them and PCAPS and I already see the notes about Tuning with UEBA (which is part of our jobs like it or not if your more on a blue team focus).
Though wondering if we are going to make it that far tomorrow. Regardless of were we get there is going to be a lot of good info and some shenanigans along the way!
On 1/23/2020 I attend a webinar from the fine folks at Black Hills Information security on an into to Cyber Deception (aka Honey pots). As someone who might be getting shifted into a more proactive security role versus all the things I handle now I was really interested in this subject.
What really though me off was how John Strand tied this very thing into more applicable threat intelligence. As someone who was also intrested in Cyber threat intel. Mostly steaming from the fact I could of done intel when I was enlisted, but chose logstiics because it used computers…Anyway. Getting threat feeds and currently working with Minemeld at work as well to help automate some of our responses to known IoC. The interesting and kinda “bad” about feeds is that they only deal with IoC’s that have hit all kinds of industries and who knows how old they could be after IR and forensics teams got the info out, there very well could be old now. They also do not deal with active threats hitting your enterprise, so you could be blocking a bunch of threats that have nothing to deal with your enterprise and could have attacks going on not getting blocked or looked at. This really hit me as something that is useful being able to get an attacker trapped in a honeypot and alerting on a honey account (an admin type account that no one should have access too so it can alert on SIEM or some other tool of your choice). with this going on you can look for IoCs possible C2 servers and the possible attack vector being used along with possible source IPs.
Black Hills Information Security Honey Pot Linux distro Active Defense Harbinger Distribution (ADHD)
What was also good about this webinar as I learned about Active Defense Harbinger Distribution(ADHD). Similar to Kali or even Flare-VM with how they handle pentesting or reverse engineering, ADHD handles with setting up honeypots. The tools are welly documented and have a basic walk-though with each tool. I will need to get some time fully go into using this for testing on my lab to see how these function more. This will also be a combo as I can use this traffic I generate attacking these honeypots to further learn some packet/traffic analysis as well. Still before I fully go after this I think I might need to finish setting up my Security Onion server and my FortiGate firewall.
I’d like to thank Black Hills Information Security for this great webinar, I wish I had taken some better notes or had the time to configure ADHD before posting this, hopefully I’ll get some tinkering this week.